Is science advanced by a small group of scientists or is it more of a large scale collaboration? Answer to this question is pretty crucial, because it largely influences what kind of interventions are best to improve science and knowledge creation. For example, if we found that science is advanced by a small group of scientists rather than by every scientist in a large scale collaboration, then we might further think about how to grow this small group or how to empower them and perhaps let off the others if growing is not possible.
Small group vs large scale collaboration
One of the good treatments of this question I’ve read so far is this post by José Luis Ricón. My aim here is to quickly summarize its findings and then generate some more unexplored questions that might fill in the blank spaces on the map or might help to make the answers more actionable.
This debate could be framed as Newton vs Ortega hypothesis, where Newton hypothesis is a view that top researchers build on the work of other top researchers and most of the other (average) science doesn’t really matter, whereas the Ortega hypothesis is a view that large numbers of average scientists contribute substantially to the advance of science through their research.
This post by José Luis Ricón looks at some evidence for both of these hypotheses and concludes that Newton hypothesis is likely correct and Ortega hypothesis false. The strongest evidence in favor of this conclusion seems to be a study by Cole & Cole (1972) and later by Bornmann et al. (2010), which show that most cited papers cite mainly other most cited papers and only rarely cite less cited papers. At the same time, other less cited papers also cite mainly the most cited papers and to a lesser extent (but still more than the most cited papers) cite the less cited papers. See this in a figure from Bornmann et al. (2010):
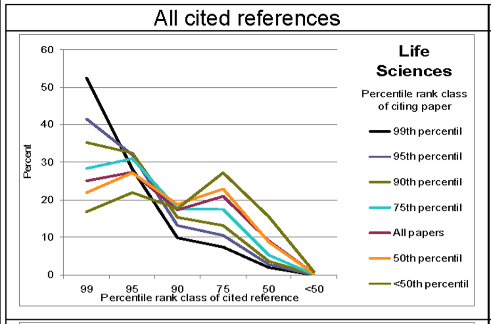
The distribution of impact across researchers also seems to be highly skewed, which excludes another potential version of Ortega hypothesis: that everyone tries to get to the frontier and throughout their career, many people succeed, push the frontier a little bit forward but then fall back and stay behind again for the rest of their career – if that was the case, the distribution of citations across researchers would be less skewed and more uniform than it actually seems to be.
Why is that?
We might ask: Why is that? Why do some researchers produce max more impact than others? Here are couple potential answers:
1) It’s genetic – people at the frontier have some superficial combination of genetic traits that are impossible to learn (e.g. combination of very high intelligence, conscientiousness, need for cognition,..).
But if that was true, then we can argue that the raw population numbers increased a lot during the second half of the 20th century and we should see a proportionately large increase in the total number of positions at the frontier (because more people with this superior mix of skills have been born) – did we see that?
2) It’s behavioural – people at the frontier do something differently than all the others and this can be taught/learnt. Maybe it is the choice of which papers to read, how to distribute their attention, how to ask questions that yield more fruitful answers, how to design the research so it is robust, etc… Evidence in this direction could be that top scientists tend to be trained by other top scientists, as observed on Nobel laureates, National Academy members, and other eminent scientists (Cole & Cole, 1972). Similarly, early co-authorship with top scientists predicts success in academic careers (Li, Aste, Caccioli & Livan, 2019). Maybe there is something hidden in the training process which causes researchers to become excellent. This would be good news, because as long as we can figure out what this is, we can scale it up and train way more researchers in this way, adding many more excellent researchers to the pool.
3) It’s systematic – the limited number of positions must be limited because of some feature of the system. For example, attention (expressed via citations) is a limited resource and always just 5 people can get the full attention, regardless of how many other people there are, whether it’s 5 or 500. Knowledge or quality of work doesn’t seem to be limited in this way (e.g. it is permissible to imagine 500 scientists doing the highest quality work at the same time instead of just 5 scientists), but attention is and that may create dynamics as described above. Moreover in deciding where are we going to allocate our attention, we might use heuristics like “following the work and students of those who already proved to be impactful” which would be in line with the notion that top scientists tend to be trained by other top scientists and early co-authorship with top scientists predicts success in academic careers – only this time this relationship would appear not because of the “inner quality” of these apprentices, but rather because of Matthew effect (see more discussion below).
Another version of this is that there is some unique combination of resources (e.g. concentration of talent) that makes it much more likely scientists to rise to the top. This would explain why top scientists often come from the same few universities. Good thing is, that this might be perhaps easier to replicate and thus increase the total number of top scientists.
Alternative explanation: Matthew effect
The alternative explanation of the Bornmann et al. (2010) data above could be the existence of Matthew effect alas extremizing of the distribution of paper quality via self-reinforcing mechanisms resulting in more skewed distribution not tracking the differences in quality accurately (via Turner & Chubin, 1976). For this, Ricón mentions several studies studying Matthew effect via effects of prestige on the number of citations a given author gets. One way to study this is to look at how the number of citations of an author’s previous work changes after they receive a prestigious award/grant, relative to the control group (see Azoulay et al., 2013; and relatedly Li et al., 2020). Another, perhaps a bit weaker, method, is trying to explicitly control for prestige as a mediator in the relationship between higher scores given by the funder in the grant proposal assessment and higher citation performance later (see Li & Agha, 2015). These studies conclude that the effects of prestige are either very weak or non existent, and thus the main differences in number of citations are likely caused by differences in actual quality of these papers/authors.
However, prestige might not be the only, or even the most important, way how Matthew’s effect plays out and causes the skewed distribution of impact. Consider this scenario: As a scientist, you have limited time to spend reading papers. Which papers will you choose to read in order to get the best understanding of a given issue? Perhaps the most cited papers since these seem to have been most useful to other scientists. Then your time for reading papers runs out and you write your own paper – which studies are you going to cite? The already top-cited studies, because these are the ones you managed to read. And thus you’ll contribute to the self-reinforcing mechanism of Matthew effect. Anyway, let’s say that already highly cited papers are a bit old because it took time to collect these citations and you want to be ahead. Ideally, you would like to read papers which are not yet highly cited, but will become highly cited in the future – what mechanism are there to find these papers? Perhaps the most established mechanism is journal impact factor ranking. Journals are kind of prediction machines for future citations (indeed, that seems to be their main role now as they are not necessary for the dissemination of knowledge in the internet age when you can upload your paper just about everywhere, they also don’t seem to safeguard against less replicable/true research) so reading papers from high impact factor journal first would make it more likely for you to spot future highly cited papers. Anyways, similarly to the previous case, you are more likely to cite papers from these journals since this is the literature you have read, and thus actually cause the self-fulfilling prophecy of those papers from those journals being more cited. Note that this mechanism seems to operate regardless of the true value of given papers. The gatekeepers of true value are in this case high impact journal editors who kind of decide which papers will get cited in the future. This scenario could be empirically tested by surveying which papers (e.g. in terms of journal IF or number of citations) researchers (ideally broken down to top vs average scientists) tend to read (e.g. via reference managers like Mendeley, looking at what papers they spend some significant time reading rather than what papers they just save to read later).
What Newton hypothesis suggests if true?
Anyway, let’s imagine the Matthew effect does not play a large role and the differences in contributions to scientific advancement (differences in citations) are actually that skewed with science being advanced by a small group of top researchers, building on each other’s work. What ramifications does that have in real life?
Firstly, we might want to stop focusing on average metrics when assessing science and move to focus on the best case analysis. Metrics like the average number of citations across funded projects or dollars spent per citation are pretty meaningless when it’s driven by outliers who are actually the only ones pushing science forward.
In the same vein, we might want to take a stance on the question of whether to fund smaller number of exceptional researchers and give them extra resources or distribute the funding among greater number of average scientists (which often promises better dollars per citation ratio – but these average citations are perhaps meaningless since they don’t add up to a few pieces of great work), especially when we are able to predict to some extent who will become top scientist.
Further, the Newton hypothesis also diminishes the importance of many meta-science topics – for example, we might not need to push so hard to establish open science behaviours among all researchers. We might be just ok if e.g. the top 10 % cited papers will be all open access to grab all the benefits that open access promises. We don’t need the remaining 90 % of papers to be accessible because they just matter far less. Perhaps this would also save a lot of money that would otherwise be paid for enabling open access to papers which are not read and cited anyways (that is if we chose to provide open access via the gold way, which is in my opinion wrong strategy anyway. Maybe we should measure progress in open access and open data not via the total ratio of open access/data papers, but rather via looking at how large the ratio of top 10 % cited papers which have open access/data is. Further, we might not care that much about pre-registration, reporting standards, etc.. of all scientists – maybe it’s enough if the top 10 % papers adhere to these standards. Targeting the interventions in this way might also be more manageable than trying to cause a cultural change among all scientists.
We could also think bigger picture and ask whether it would be sensible to lay off e.g. the less cited half of scientists and either invest the money in something else or redistribute it to the more cited half of scientists, creating better conditions for them and making the science jobs more attractive. I will not go deeper into this discussion but you can find some argumentation in Ricón’s post
Can we grow it?
Instead of (or simultaneously with) getting rid of less cited scientists, we might focus on how to grow the number of top scientists. Is it even possible to grow it? The answer to this will perhaps depend on the underlying reasons why the top scientists are top, as discussed above. Anyway, we can also look at some pieces of direct empirical evidence:
One piece of evidence pointing towards “not possible to grow much” is the notion that despite large increases of funding and number of researchers, the rate of economic growth has not increased. However, this tracks only economic impacts of science and is perhaps not a good metric of it anyway.
Another experiment cited by Ricón is Cole & Meyer (1985) who looked at number of hired assistant professors in physics between 1963 and 1975

and compared it to proportion of physicists that ended up being cited:
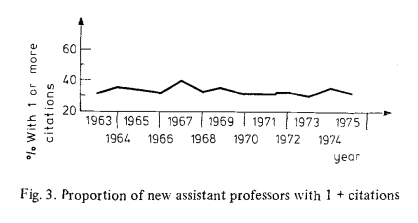
showing that the proportion of physicists with 1 or more citations stayed the same even though their absolute number increased and then declined in this time period. This suggests that growing the absolute number of cited researchers is possible – however, we might want to use stricter criteria for top scientist than “having 1 or more citations”.
Conclusion
It seems that distribution of scientific impact is highly skewed both across papers and across researchers and that top papers/scientists are the main contributors to future top papers/scientists, suggesting that Newton hypothesis is true. Anyway, the extent to which this reflects true value is not necessarily clear, because the same dynamic could potentially be created (or at least supported) by the Matthew effect and distribution of attention. Further this finding might be disputed if there is some value causing the scientific progress that is not tracked by citations (which I plan do have some future post about).
If the Newton hypothesis about true distribution of scientific impact is true, then we might want to change the way we measure scientific success (moving to best cases analysis rather than aggregated average metrics) as well as what kind of programmes we support (perhaps stop supporting the average science). We might consider laying off some part (e.g. half) of the less cited scientists and redistributing the funding to support more cited scientists or elsewhere. At the same time, we might want to think more about and experiment with growing the number of top scientists.
In some future post, I would also like to look at another question that could help us understand how the scientific progress works – whether the progress happens via big jumps (similar to Kuhnian revolutions), small incremental steps or some other models and comparing the empirical evidence for this in different fields. This could give a better picture on whether the progress has the same dynamics and shape for science as a whole or whether different fields work differently.